- Services
- Data Analysis services
-
Data Analysis services
-
- Meta-Analysis Research services
-

Meta-Analysis Research Services
-
- Data Collection Services
-
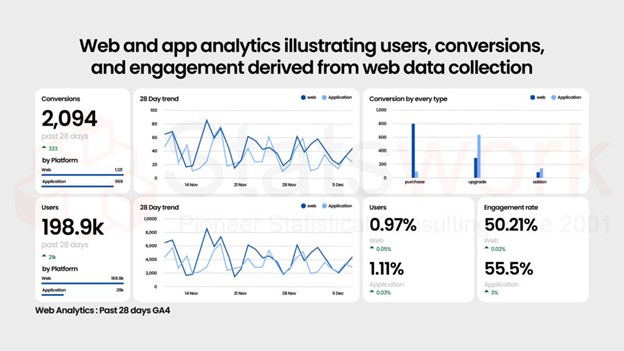
Data Collection Services
-
- Statistical & Biostatistics services
-
Statistical Programming & Biostatistics services
-
- Data Management Services
-
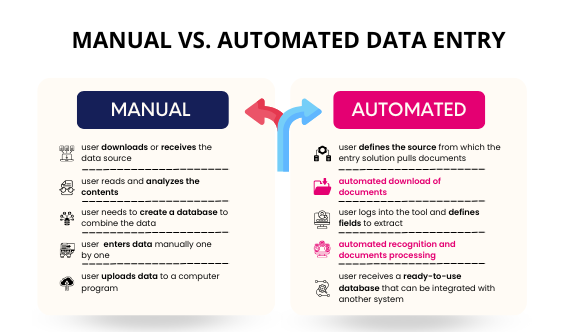
Data Management Services
-
- Research methodology services
-
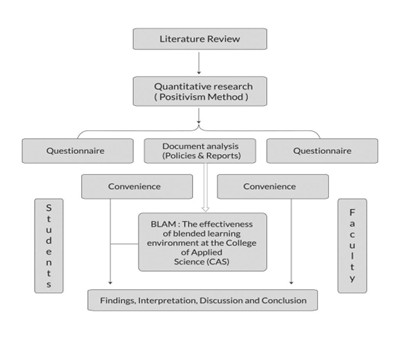
Research methodology services
-
- Tool Development Services
-
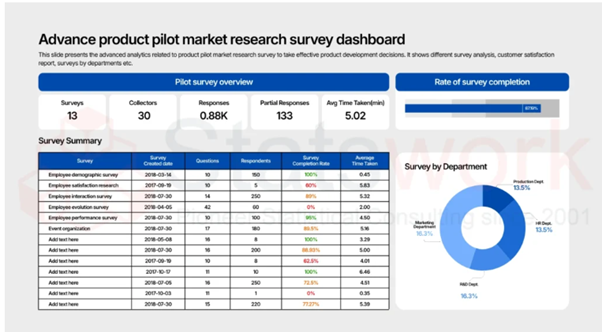
Tool development services
-
- Statistical Interpretation services
-
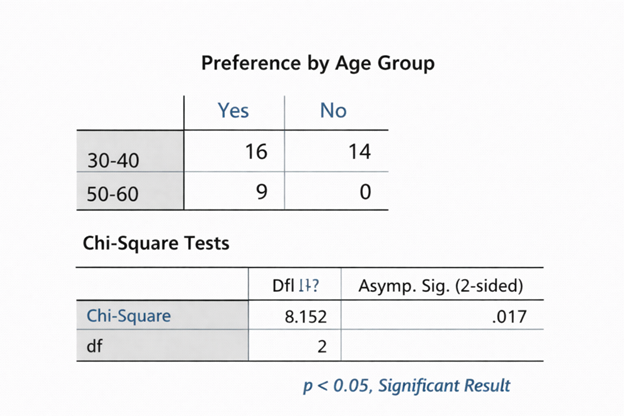
Statistical Interpretation services
-
- Sample Size Calculation Services
-
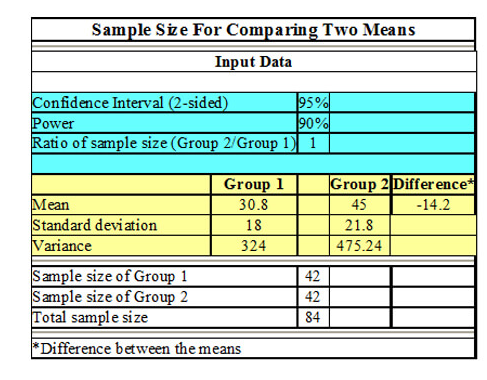
Sample Size Calculation Services
-
- AI & ML Services
-
Artificial Intelligence and Machine Learning Services
-
- Report Generation Services
-

Report generation Services
-
- Data Analysis services
- Services
- Data Analysis services
-
Data Analysis services
-
- Meta-Analysis Research services
-
Meta-Analysis Research Services
-
- Data Collection Services
-
Data Collection Services
-
- Statistical & Biostatistics services
-
Statistical Programming & Biostatistics services
-
- Data Management Services
-
Data Management Services
-
- Research methodology services
-
Research methodology services
-
- Tool Development Services
-
Tool development services
-
- Statistical Interpretation services
-
Statistical Interpretation services
-
- Sample Size Calculation Services
-
Sample Size Calculation Services
-
- AI & ML Services
-
Artificial Intelligence and Machine Learning Services
-
- Report Generation Services
-
Report generation Services
-
- Data Analysis services

















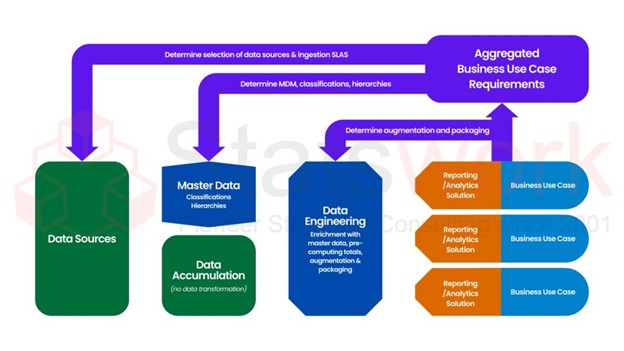
Gathering Requirements
As planned the initial step is to gather the requirements for the project - project goals, data types, and specific information unique to the domain.
Data Preparation
Your raw data will be cleaned and prepared before annotation.
Guidelines Creation
We define annotation guidelines and quality standards.
Production
Your project is executed with quality monitoring.
Evaluation
We perform QA and improve accuracy.
Final Delivery
Final dataset is delivered in required format.


Thanks to the precise medical image annotation provided by the team, our AI model achieved clinical-grade accuracy. This directly contributed to our publication in the Journal of Medical Imaging and Health Informatics.
— CTO, HealthTech AI Startup,
- USA

We were impressed by the team's expertise in clinical text annotation. Their work helped us build an NLP pipeline that led to our successful article in the International Journal of Medical Informatics.
Lead Researcher, Clinical Research Organization,
- UK
The annotated dataset they delivered met all journal standards, and their adherence to HIPAA compliance was commendable. Our study was published in the BMC Medical Informatics and Decision-Making journal.
Principal Investigator, Healthcare AI Lab,
- Canada
The Statswork team helped us annotate and label a massive dataset for drug discovery, contributing to our manuscript accepted in Frontiers in Pharmacology. Their scientific accuracy was outstanding
Senior Scientist, Pharma Research Unit,
- India

