

What Is Text Classification and How Is It Used in Natural Language Processing?
- Home
- Insights
- Article
- What Is Text Classification and How Is It Used in Natural Language Processing?
Qualitative Research Service
News & Trends
Recommended Reads

Data Collection
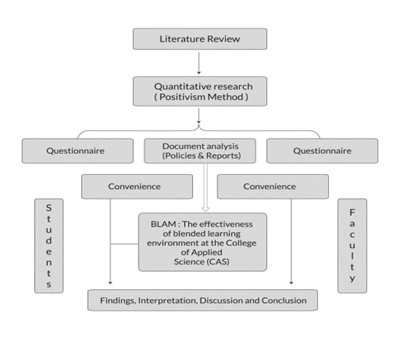
As the data collection methods have extreme influence over the validity of the research outcomes, it is considered as the crucial aspect of the studies
- 1. Introduction
- 2. DeepHealth’s Diagnostic Suite™: Revolutionizing Radiology Workflows
- 3. Key Features
- 4. AI Impact on National Screening Programs
- 5. SmartMammo™: Enhancing Breast Cancer Screening
- 6. DeepHealth AI Use Cases Across Specialties
- 7. Strategic Collaborations and Ecosystem Expansion
- 8. Impact and Adoption of DeepHealth’s AI Solutions
- 9. Conclusion: The Future of Radiology with AI
- 10. References
In the era of digitization, huge amounts of textual information are being generated by the second. The need for fast processing of such huge volumes of information is inevitable. Natural Language Processing (NLP) involves Text Classification that enables the analysis of the information contained within them.
What is Text Classification
- Text Classification can be defined as the process of categorizing or classifying text into various predefined classes depending on their meaning and context in Natural Language Processing.
- Text Classification contributes in a big way in helping convert text data to structured data format. This helps in making the processing of such data by machine learning much easier.
- This is very common in emails, social media platforms, document management, customer review sites, and so forth.
- It plays an important part in helping to make data processing simple. This is achieved through the use of various Natural Language Processing (NLP) techniques and algorithms [1].
How Text Classification Works
- Text Preprocessing: Raw texts undergo pre-processing through the elimination of noise from the text such as punctuation marks and stop words.
- Feature Extraction: TF-IDF method is used to convert text to numeric form, which is part of the text mining process.
- Model Training: Models are trained on datasets to be able to understand and classify data.
- Prediction and Evaluation: The classified data is analyzed to check whether it is correctly classified.
Types of Text Classification
Various kinds of text classifications are applied according to the kind of task and results required.
| Type | Description |
| Binary classification | Categorizing the text either into two possible categories based on its content (For example, spam mail or not spam mail). |
| Multi-class classification | Putting text under one category out of many pre-defined classes based on the meaning of text (For example, news categorization as sports, politics, or technology) |
| Multi-Label classification | Enabling categorizing of text into multiple categories at once (For example, tagging of blogs according to topics). |
| Hierarchical classification | Putting text into the category in the form of a hierarchical structure or parent-child structure (For example, product categorization in e-commerce websites). |
| Sentiment classification | Determining the sentiment tone of the text (For example, customer review classification as positive, negative, or neutral). |
Applications of Text Classification in NLP
Text classification is an important technology for interpreting large amounts of written content, automating processes, and developing valuable insights; all of which enable companies to operate more effectively and to base their decisions on data.
- Customer Feedback Analysis: Sentiment analysis allows organizations to know the views of their customers and solve their problems, leading to increased satisfaction.
- Spam Detection Systems: Spam detection systems allow users to receive emails that they need without being exposed to spam.
- Content Categorization: Text classification organizes blogs, articles, news items, and other text content to increase its discoverability.
- Chatbots and Virtual Assistants: Intentions of users are identified by the systems through text classification [3].
Text Classification Benefits in NLP
Text classification is an NLP technique that supports efficient classification and organization of large amounts of content.
- Improved NLP Accuracy: Algorithms are used in determining how a model recognizes context and interpretation by categorizing the input data.
- Automated Text Processing: Software systems allow users to automatically analyze emails, reviews, or social media postings which greatly reduces the amount of time spent analyzing messages.
- Scalability: Through the usage of text classification, NLP model can access thousands of documents in a very short time.
- Support for Advanced NLP Tasks: Structure will allow for improved output for applications such as sentiment analysis, topic identification, and responding to customers via a chatbot [4].
Challenges of Text classification in NLP
Text classification, like all parts of NLP, has limits in its ability to define its success.
- Context and Nuance: Sarcasm, ambiguity, and subtlety can cause models to misclassify.
- Dependence on Labelled Data: To train models, we need to build high-quality datasets that require an extensive number of resources and time.
- Language Evolution: NLP systems need to adapt as slang, jargon, and terms change.
- Multilingual Complexity: For text classified in multiple languages, we will need common grammar and cultural context models to develop the language [5].
Conclusion
Text Classification is one of the most effective tools of Natural Language Processing that allow computers to understand human language. Using the power of natural language processing, text mining and text classification technologies, companies can obtain useful information about their data.
With the development of technologies, text classification is expected to become even more relevant.
StatsWork Delivers Precise Data Annotation to Power Your Text Classification Projects!
Reference
- Kowsari, K., Jafari Meimandi, K., Heidarysafa, M., Mendu, S., Barnes, L., & Brown, D. (2019). Text classification algorithms: A survey. Information, 10(4), 150. https://doi.org/10.3390/info
- Jindal, R., Malhotra, R., & Jain, A. (2015). Techniques for text classification: Literature review and current trends. webology, 12(2). https://www.academia.edu/
- Dogra, V., Verma, S., Kavita, Chatterjee, P., Shafi, J., Choi, J., & Ijaz, M. F. (2022). A complete process of text classification system using state‐of‐the‐art NLP models. Computational Intelligence and Neuroscience, 2022(1), 1883698. https://doi.org/10.1155/2022/
- Sokolova, M. (2018). Big text advantages and challenges: classification perspective. International Journal of Data Science and Analytics, 5(1), 1-10. https://doi.org/10.1007/s41060
- Kesiku, C. Y., Chaves-Villota, A., & Garcia-Zapirain, B. (2022). Natural language processing techniques for text classification of biomedical documents: a systematic review. Information, 13(10), 499. https://doi.org/10.3390/info