
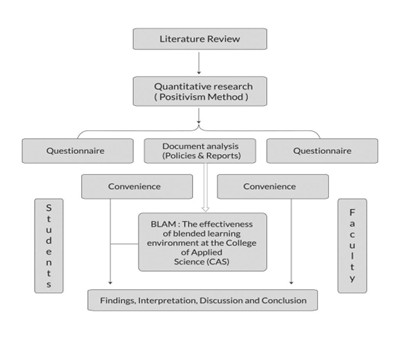
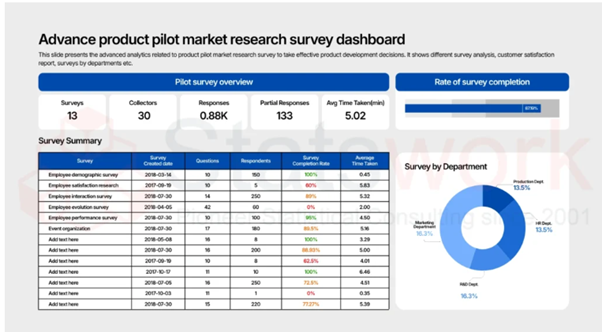
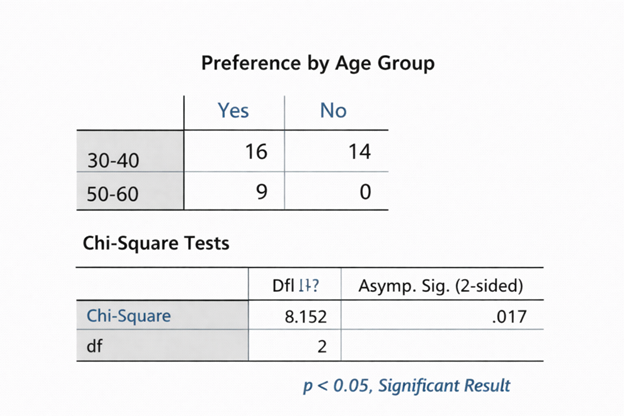
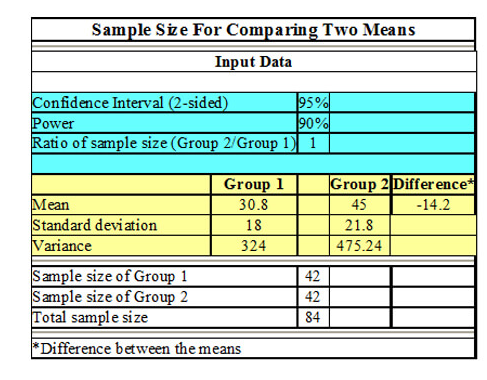


Custom Algorithm Development Services
Our professional build algorithms to your specification for any business purpose such as predictive, classification or optimization. We keep tabs to ensure your models remain accurate and scalable while keeping the overall objectives of the task before them.

Model Evaluation & Validation Services
We make certain your models are evaluated rigorously with standard industry evaluation methods using metrics such as cross-validation, ROC analysis, and precision-recall scoring to maintain that the output from your models is accurate and trustworthy.

Feature Engineering & Data Preparation
We convert raw data into useful high-impact feature data, normalize the data as needed and select subset of most informative variables – that leads us to reduce the noise to improve overall model performance.

Model Tuning & Optimization Services
We optimize algorithm parameters by implementing grid search, random search or even Bayesian search methods to enhance model accuracy and efficiency.










Engaged domain and data science experts (3 expert reviewers per project)

A trusted partner to develop a reliable, performant model for every industry

Rapid development cycle allowing scalable algorithm deployment support

Transparent, explainable AI per industry standards






1. Defining Use Cases and the Business Process Flow
Start by clearly identifying what your business needs. A single application can serve multiple functions, and each function may have several use cases. We work closely with you to define these use cases before establishing detailed business requirements. Our team of developers and domain experts collaborates to map out the complete business process flow—breaking it down into inputs, outputs, and sub-processes, and identifying the sequence, interactions, and decision points that shape your operational model.

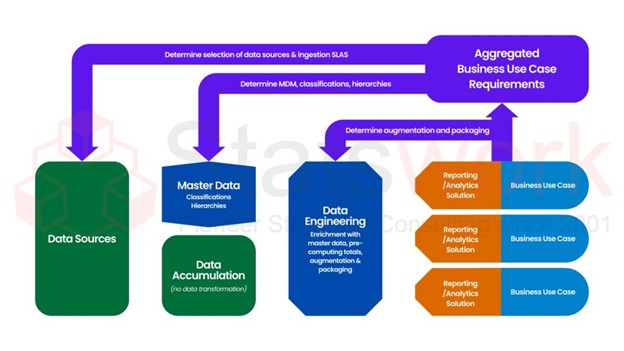
2. Developing a Data Dictionary & Capturing Existing Data
A well-defined data dictionary is essential for understanding, contextualizing, and translating programming logic into actionable business rules. Once the process flows are documented, our experts create a comprehensive data dictionary that includes all data elements used in the application, along with their business and functional definitions. We then establish reliable data collection mechanisms to ensure completeness and accuracy from the start.

3. Visualizing the Data Pipeline
We help you define and implement the components of a data pipeline by developing business rules, annotations, and metadata categorization. This includes designing the system architecture and conceptual framework to meet your specified requirements. Our approach incorporates relevant certifications, regulatory requirements, and market constraints. We define the methodologies to be used in the software development process and follow best practices aligned with industry standards.

4. Developing, Validating & Deploying Data Models
Machine learning models can quantify the conceptual similarity of fields irrespective of labels (e.g. Patient_ID and PID), encouraging greater precision comparing datasets with unrelated labelling conventions.

5. Delivery & Ongoing Support
The processed data will be delivered to you according to the agreed timescales and we will continue to support you in your efforts to get value from it (and therefore your AI & ML solutions).

6. Audit Trail
Maintaining a detailed audit trail to ensure traceability and compliance throughout the data processing lifecycle.


"Statswork helped us design a predictive model that reduced our loan default rate by over 30%. Their team translated complex financial data into a scalable solution that is both accurate and explainable."
— VP of Risk Analytics,
Leading FinTech Company

"We needed an algorithm that could handle massive healthcare datasets while maintaining compliance. Statswork delivered a model that not only improved diagnostic accuracy but also passed all regulatory checks with ease."
— Clinical Data Lead,
Healthcare Analytics Firm
"From model development to deployment, Statswork was a true partner. Their ability to blend technical depth with domain understanding made a major difference in our product launch timeline."
— Head of Data Science,
AI Product Company
"Statswork’s team helped us optimize our marketing strategy using custom classification algorithms. We saw a 25% boost in campaign effectiveness within weeks of implementation."
— Marketing Director,
Global Media Agency

