


Applications of Statistical Analyses on Water Quality data and its recent research trends
April 15, 2021
Various ways during which Analytics help Enterprises drive Business Growth
April 30, 2021How to establish and evaluate clinical prediction models
Introduction
The use of a parametric/semi-parametric/non-parametric mathematical model to estimate the probability that a subject currently has a certain condition or the possibility of a certain outcome in the future is referred to as a clinical predictive model. Various regression analysis approaches are used to model clinical prediction models, and the statistical nature of regression analysis is to find “quantitative causality.” To put it another way, regression analysis is a quantitative assessment of how much X impacts Y. Multiple linear regression models, logistic regression models, and Cox regression models are all widely used approaches. The secret to statistical analysis, data modelling, and project design is assessing and verifying prediction models’ efficacy. It is also the most challenging aspect of data analysis technology.
Clinical Prediction Model
A clinical prediction model is a tool used in healthcare to measure estimates of the likelihood of the future course of a specific patient outcome using multiple clinical or non-clinical predictors. A realistic checklist for developing a valid prediction model is presented in a clinical prediction model. A clinical prediction model can be used in various clinical contexts, including screening for asymptomatic illness, forecasting future events such as disease, and assisting doctors in their decision-making and health education. Despite the positive effects of clinical prediction models on practice, prediction modelling is a difficult process that necessitates meticulous statistical analysis and sound clinical judgments.
Steps to establishing a clinical prediction model
There exist several types of research detailing the methods to construct clinical prediction models. However, there is no proper method to construct the prediction model in medicine. The construction and evaluation of prediction models are classified into five steps.
Step 1:Gathering the ideations and questions for enhancing the model.
It incorporates structuring the research questions, such as finding the target variable for predicting which age group of the targeted people you want to predict.
For instance, gathering one patient details and use it as a trained data set to test the other data set of another patient’s details. [1].
Step 2: Selection of data
Data collection is a vital part of statistical or clinical research. Nevertheless, the perfect data and a perfect model can’t exist. It would be nice to look for the most appropriate.
| S.NO | DISEASE | SYMPTOMS |
| 1 | CANCER | Unusual lump, changes in the mole, cough and hoarseness, unusual diarrhoea and constipation |
| 2 | CARDIOVASCULAR DISEASE | Chest pain, numbness, shortness of breath, weakness and chest tightness. |
| 3 | ARTHRITIS | Pain in the hip or joint, swelling, colour changes in the skin, loss of appetite. |
| 4 | DIABETES | Darkened area of skin, High blood pressure and cholesterol levels |
The primary dataset with the endpoint of the study and all key predictors may not be available at all the time. Secondary or administrative data sources are mandatory. Based on the various data types of datasets, prediction models can be utilized.
[2] For instance, the epidemiology study is based on the Data Mining systematic approach.
Step 3: Ways to handle variables
Most of the time, researchers may face challenging situations where the variables are highly correlated to each other, excluded in the study. Variables don’t show statistical significance or the petite effect size. But it will contribute to the predictive model. Researchers will handle the missing data problems, categorical data, etc., before getting the interference.
Clinical prediction models CODE:
| Code number | Disease/ Deficiency |
| ICD-10-R50 | fever |
| ICD-R05 | cough |
| ICD-10-CM-R52 | pain |
| ICD-9-CM-784.0 | headache |
The Bayesian network was implemented to manipulate the independent variables of some diseases in the crucial stage of treatment. This model predicts and offers a way to handle the disease along with preventive measures [3].
Step 4: Generating model
There are no proper rules to select a particular model for the statistical analysis. There are some standard methods to build a model using Linear regression analysis, logistic regression analysis, and Cox models.
Sometimes the clinical data encounters over-fitting of the model and its results in as estimates. This over-fitting issue can be detected using Akaike Information Criteria or Bayesian Information Criteria. The smaller AIC and BIC values result in a good fit for the model.
[4] Using Multivariate prediction models for analyzing the different characteristics of various patients.
Step 5: Evaluation and validation of the model
After building the model, it is necessary to evaluate and validate the predictive power of the model. The key components that evaluate the model are calibration which plots the proportion, and discrimination classifies the events like success or failure. There are two types of data validation, namely internal and external validation of the model. Internal validation evaluates the model within the data, whereas external validation can be done using the re-sampling technique, usually through bootstrapping. It means creating or generating new data sets with similar characteristics to the original data and validating the study’s method through the newly created or bootstrapped data. Further, there are several statistical measures to evaluate the model. Some of them are ROC curve, AUC curve, sensitivity and specificity, likelihood ratio, R square value, calibration plot, c-index, Hosmer-Lemeshow test, AIC, BIC, etc.
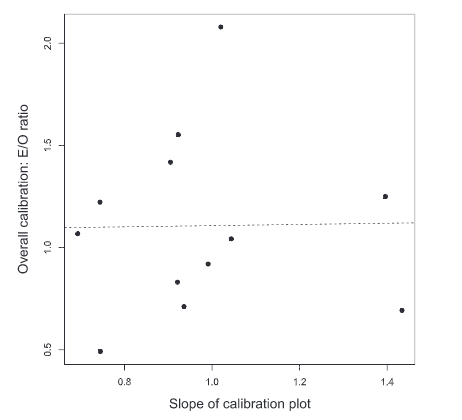
Figure 1: Slope of Calibration plot – Source: Stevens and Poppe (2020)
Besides, Stevens and Poppe (2020) suggested the Cox- calibration slope using a logistic regression model instead of using the predictive model’s calibration slope. It suggestion has been made after the scrutiny of around 33 research articles and found that most of the validation is external validation and identified the validity using the calibration slope.
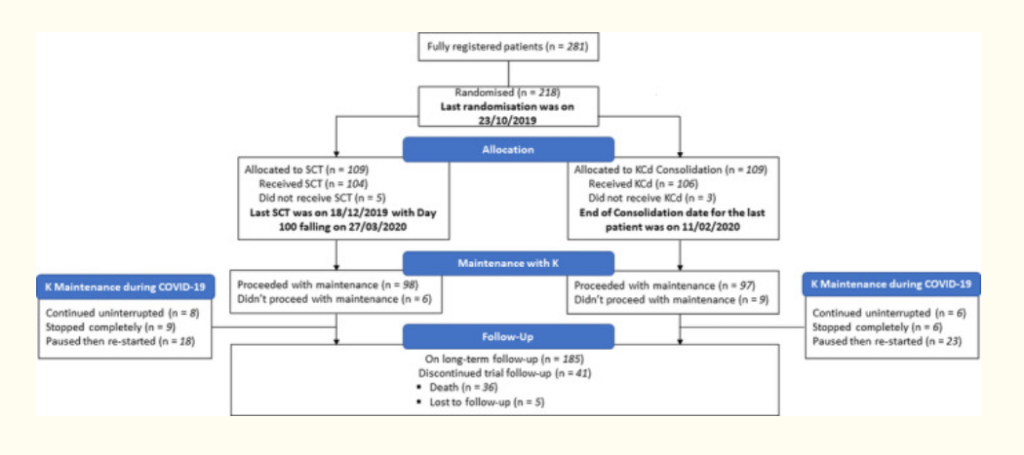
Figure 2: This flow diagram illustrates the progress through the various phases of the CARDAMON phase II clinical trial, including the impact of COVID‐19 on the 70 patients on maintenance K across the two treatment arms at the start of the lockdown period. The 15 patients who stopped K maintenance joined the 170 patients who were already on long‐term follow‐up on 24 March 2020, bringing the number up to a total of 185. SCT, stem cell transplantation; K, carfilzomib; C, cyclophosphamide; d, dexamethasone [6].
Future Scope:
- Based on the patient details, we can predict the further severe causation of disease in the future.
- By gathering the data from a single patient may help to predict other similar patients for better treatment.
- Big data support for manipulating vast amounts of clinical trials, without complexity simultaneously with high accuracy.
TABLE 1 Concepts and Techniques of Clinical prediction models:
| S.NO | METHODS | PURPOSES | REFERENCES |
| 1 | Data Collection using Surveys | To train and test the data between two patients | [1] |
| 2 | Epidemiology study | Data mining of data sets | [2] |
| 3 | Bayesian Network | To predict the characteristics based on the independent variable | [3] |
| 4 | Multivariate analysis | To manipulate the independent variables | [4] |
References:
- Schmidt, André, et al. “Improving prognostic accuracy in subjects at clinical high risk for psychosis: systematic review of predictive models and meta-analytical sequential testing simulation.” Schizophrenia Bulletin 43.2 (2017): 375-388.
- Bagherzadeh-Khiabani, Farideh, et al. “A tutorial on variable selection for clinical prediction models: feature selection methods in data mining could improve the results.” Journal of clinical epidemiology 71 (2016): 76-85.
- Chowdhury, Mohammad Ziaul Islam, and Tanvir C. Turin. “Variable selection strategies and their importance in clinical prediction modeling.” Family medicine and community health 8.1 (2020).
- Iba, Katsuhiro, et al. “Re-evaluation of the comparative effectiveness of bootstrap-based optimism correction methods in the development of multivariable clinical prediction models.” BMC Medical Research Methodology 21.1 (2021): 1-14.
- Stevens, R. J. and Poppe, K. K. (2020). Validation of Clinical Prediction Models: What does the “Calibration Slope” Really Measure?. Journal of clinical epidemiology, 118, pp. 93–99.
- Camilleri, Marquita, et al. “COVID‐19 and myeloma clinical research–experience from the CARDAMON clinical trial.” British Journal of Haematology 192.1 (2021): e14.


