
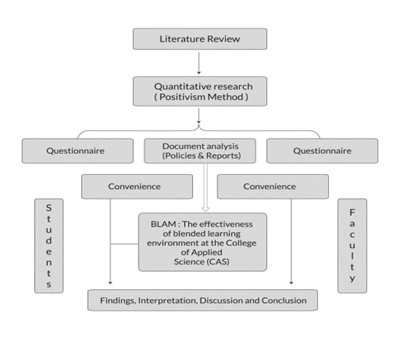
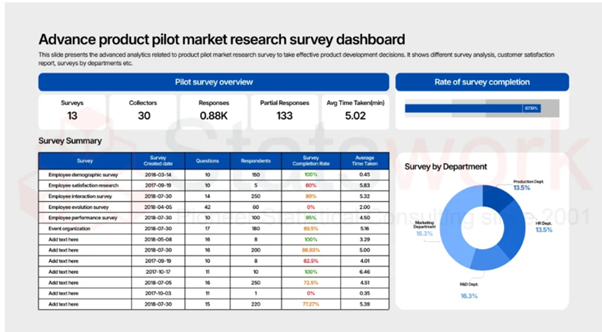
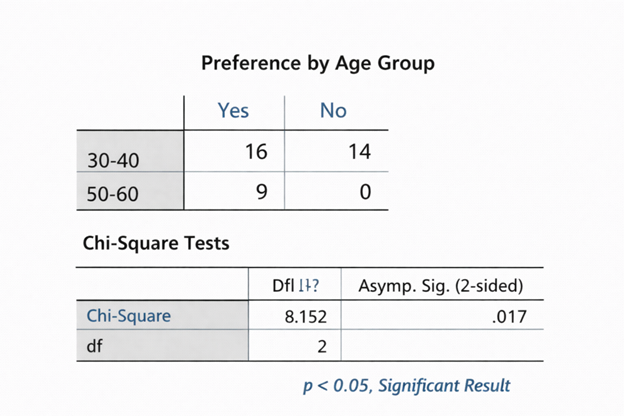
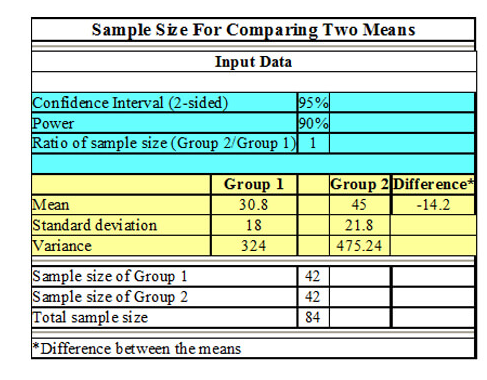


SEM Using AMOS – Guide to Structural Equation Modeling with AMOS
August 22, 2019Analysis of variance (ANOVA)
August 28, 2019Factor Analysis – Definition, Methods & Applications | StatsWork
- Home
- Blog
- Factor Analysis – Definition, Methods & Applications | StatsWork
Meta Analysis Service
Recommended Reads
Contact us
Factor Analysis – Definition, Methods & Applications | StatsWork
The analysis of variance is not a mathematical theorem, but rather a convenient method of arranging the arithmetic.- Ronald Fisher
The inexpensive Factor Analysis is a prominent statistical tool to identify a lot of underlying dormant factors. For more than a century it is used in psychology and also in a wide variety of situations.
Factor analysis explains correlations among multiple outcomes as a result of one or more factors. As it attempts to represent a set of variables by a smaller number, it involves data reduction. It explores unexplained factors that represent underlying concepts that cannot be adequately measured by a single variable. It is most popular nowadays in survey research where the responses to each question represent an outcome. It is because multiple questions are often related and the underlying factor may influence the subject responses.
The reduction technique of factor analysis in reducing a large number of variables into a fewer number of factors enables to extract maximum common variance. The common score from all variables as an index can be used for further analysis. Being part of the GLM, it assumes several assumptions including:
- There exists a linear relationship.
- There is no multicollinearity.
- Includes relevant variables into the analysis
- No true correlation between variables and factors.
From its start of psychological usage in 1904, it is now widely used in a variety of industries and fields. Its use in physical sciences to identify factors that affect the availability and location of underground sources, water quality, and weather patterns. It is also extensively and successfully used in the marketing field and market research related to product attributes and perceptions. Along with other Quantitative Research and Quantitative Analysis tools, it is used in the construction of perceptual maps and product positioning studies.
Many social scientists are seeking the help of factor analysis to uncover major social and international patterns when confronted with
- Entangled behavior
- Unknown interdependencies
- Masses of qualitative and quantitative variables
- Big data
Factor analysis capabilities:
Factor analysis helps to find solutions for a social scientist with capabilities like:
- To simultaneously manage over hundred variables.
- Compensate for random error & invalidity.
- Disentangles complex inter-relationships into their major & distinct regularities.
Factor analysis through inexpensive has its costs, including:
- Its mathematical complications.
- Entails diverse & numerous considerations in the application.
- Strange terms in technical vocabulary.
- Huge Analysis Reports covering most of the pages leaving less space for methodological introduction or explanation of terms.
- Students unable to learn it in their formal learning.
All these costs make factor analysis results incomprehensible for non-specialists, social scientists, and policymakers to identify its nature and significance.
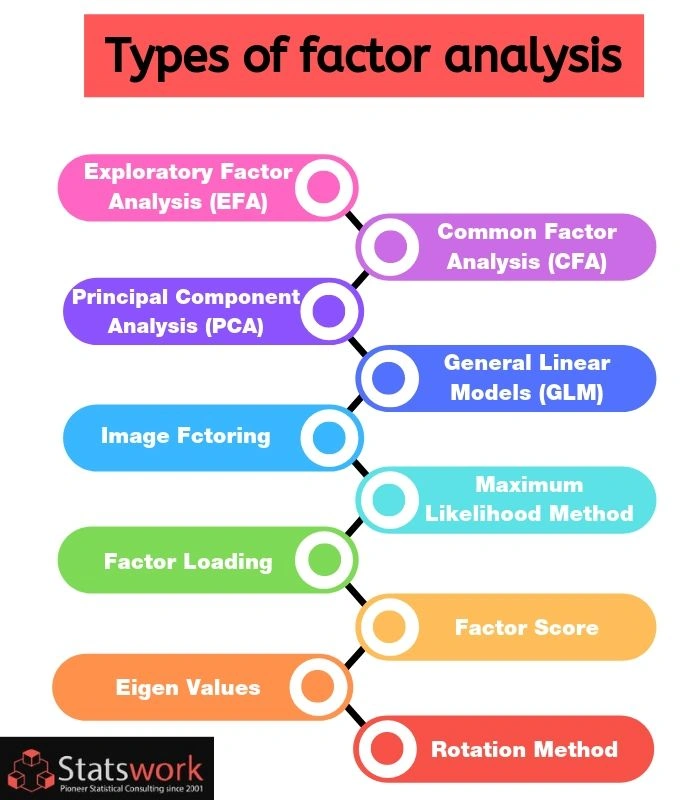
Types Of Factor Analysis
There are many methods which extract factor from data set differently, including
EFA (Exploratory factor analysis)
EFA is the most common factor analysis method used in multivariate statistics to uncover the underlying structure of a relatively large set of variables. EFA assumes that any indicator or variable may be associated with any factor to identify the underlying relationship between measured variables. It is not based on any prior theory and uses Multiple Regression and partial correlation theory to model sets of manifest or observed variables.
CFA (Confirmatory factor analysis)
CFA is the second most preferred method to extract the common variance and put them into factors. It determines the factor and factor loading of measured variables. It also confirms what is expected on the basic or pre-established theory by assuming that each factor is associated with a specified subset of measured variables.
CFA commonly uses two approaches
-
The traditional method:
This method is based on principle factor analysis than CFA and allows the researcher to know more about insight factor loading.
-
SEM (structural equating model) method:
In Structural Equating Model (SEM) approach, it is assumed that when the standardized error term is below the absolute value of two then it is good for the factor. And if it is more than two, it implies that there is still unexplained variance left to be explained by factor.
PCA (principal component analysis)
The PCA starts by extracting maximum variance and puts them into the first factor. Then it starts with the second factor after removing the first variance and the analysis goes on until the last factor. Hence this method is most commonly used by researchers.
PCA VS CFA:
-
PCA analyzes all the variance of data while CFA does it only for the reliable, common variance of data.
-
PCA is unfit for examining the structure of data as it tends to increase factor loadings in the study with a small number of variables. But in CFA there is a hypothetical underlying process or construct involved which is not in PCA.
-
Since CFA provides an accurate result, it is the most preferred research. PCA is only a choice and could be used as an initial step in CFA to provide information regarding the maximum number and nature of factors.
GLM (General Linear Model)
GLM also known as Multivariate Regression model is a useful framework to compare how several variables affect different continuous variables. Being a linear statistical model, it is the foundation for several statistical tests like ANOVA, ANCOVA, and regression analysis. GLM is described as
Data = Model + Error
Image factoring
It uses the OLS (Ordinary Least Square) Regression method to predict the factor, and this method is based on the correlation matrix.
Maximum likelihood method
It also uses the correlation matrix and has the advantage to analyze statistical models with different characters on the same basis.
Factor loading
Being the correlation coefficient for the variable, factor loading explains variance by the variable on that particular factor.
Factor score
All analysis of factor score will assume that the variables will behave as factor scores and will move. Also known as component score, it is all of rows and columns used as an index of variables for further analysis.
Factor loading
Also known as characteristic roots, Eigenvalues portray variance explained by that particular factor out of the total variance. Eigenvalues shows how much variance is explained by the first factor out of the total variance.
Rotation method
Rotation method is not affected by Eigenvalues or the percentage of variance extracted but it affects to make it more reliable to understand the output. Rotation methods have a lot of available methods, including:
-
No rotation method.
-
Varimax rotation method.
-
Quatrimax rotation method.
-
Direct oblimum rotation method.
-
Promax rotation method.

Assumptions in factor analysis:
-
No outlier:
Assuming that there are no outliers in data.
-
Interval data:
Interval data in Factor Analysis are assumed.
-
Adequate sample size:
The case used must be greater than the factor.
-
No perfect multicollinearity:
There should not be any multicollnearity between variables in factor analysis as it is an independency technique.
-
Homoscedasticity:
Being a linear function of measured variables, factor analysis does not require homoscedasticity between the variables.
-
Linearity:
As it is based on linearity assumption, factor analysis can use non-linear variables but on transfer they change to linear variables.
The above facts of factor analysis will help in successful dissertation writing and for further assistance, seek professional help.
-
Statistical Peer Review and Its Importance in Quantitative Research
-
How Research Methodology Services Improve Research Design and Statistical Accuracy
-
How Research Planning Improves Data Collection and Statistical Analysis Accuracy
-
Meta-Analysis Statistical Visualization Techniques for Evidence-Based Research Interpretation


