- Services
- Data Analysis services
- Sample Work
Data Analysis services
- Secondary Qualitative Research Services
- Secondary Quantitative Research Services
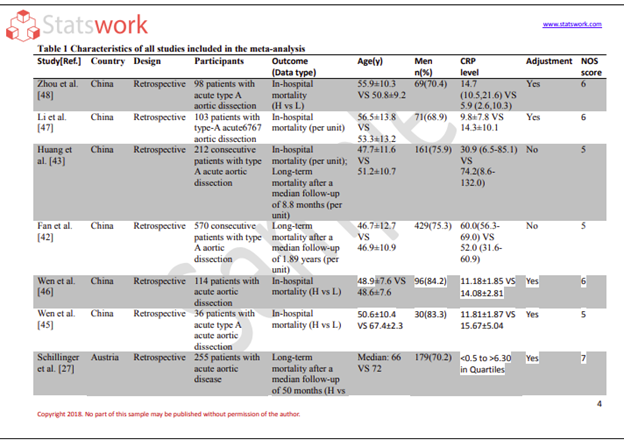
- Meta-Analysis Research services
- Sample Work

Meta-Analysis Research Services
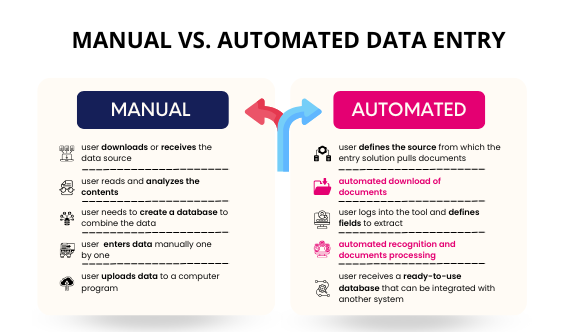
- Data Collection Services
- Sample Work
Data Collection Services
- Statistical & Biostatistics services
- Sample Work
Statistical Programming & Biostatistics services
- Data Management Services
- Sample Work
Data Management Services
- Research methodology services
- Sample Work
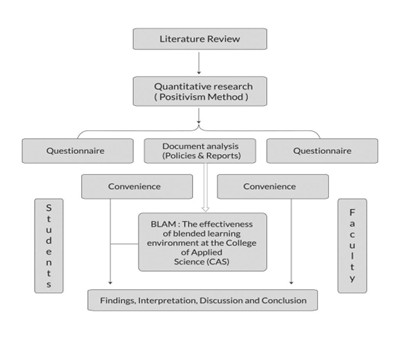
Research methodology services
- Tool Development Services
- Sample Work
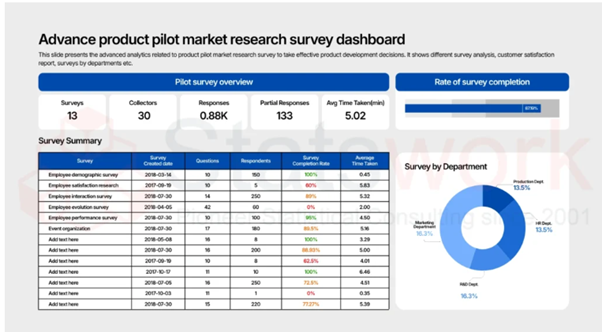
Tool development services
- Statistical Interpretation services
-
Statistical Interpretation services
- Sample Work
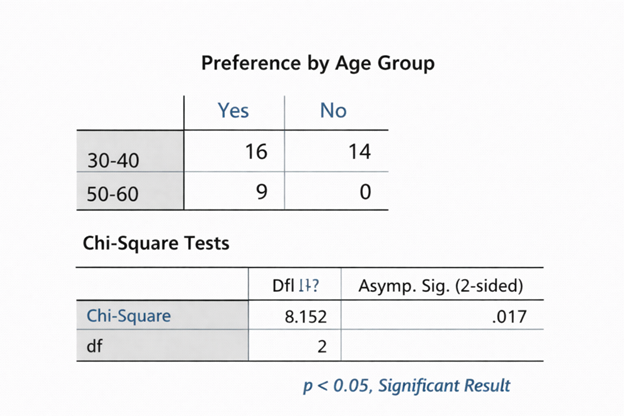
Statistical Interpretation services
-
- Sample Size Calculation Services
-
Sample Size Calculation Services
- Sample Work
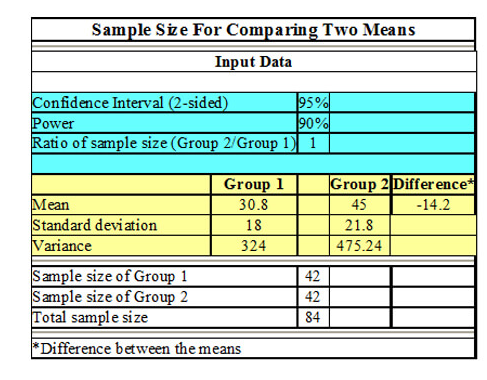
Sample Size Calculation Services
-
- AI & ML Services
-
Artificial Intelligence and Machine Learning Services
- Sample Work
Artificial Intelligence and Machine Learning Services
-
- Meaningful Visualization Services
- Thought Leadership Services
- Report Generation Services
-
Report generation Service
- Sample Work

Report generation Services
-
- Data Analysis services
- Industries
- About Us
- Blog
- Insights
- Contact Us
- Services
- Data Analysis services
- Sample Work
Data Analysis services
- Secondary Qualitative Research Services
- Secondary Quantitative Research Services
- Meta-Analysis Research services
- Sample Work
Meta-Analysis Research Services
- Data Collection Services
- Sample Work
Data Collection Services
- Statistical & Biostatistics services
- Sample Work
Statistical Programming & Biostatistics services
- Data Management Services
- Sample Work
Data Management Services
- Research methodology services
- Sample Work
Research methodology services
- Tool Development Services
- Sample Work
Tool development services
- Statistical Interpretation services
-
Statistical Interpretation services
- Sample Work
Statistical Interpretation services
-
- Sample Size Calculation Services
-
Sample Size Calculation Services
- Sample Work
Sample Size Calculation Services
-
- AI & ML Services
-
Artificial Intelligence and Machine Learning Services
- Sample Work
Artificial Intelligence and Machine Learning Services
-
- Meaningful Visualization Services
- Thought Leadership Services
- Report Generation Services
-
Report generation Service
- Sample Work
Report generation Services
-
- Data Analysis services
- Industries
- About Us
- Blog
- Insights
- Contact Us
Common Mistakes in Secondary Data Collection and How to Avoid Them
Meta Analysis Service
- What Are Common Mistakes in Secondary Data Collection?
- Common Mistakes in Secondary Data Collection and How to Fix Them
- Corporate Data Collection Mistake 1 - Utilization of Outdated Datasets
- Corporate Data Collection Mistake 2 - Not Checking Source Credibility
- Mistake 3: Not Cross Checking Data
- Mistake 4: Failure to Handle Missing Data
- Mistake 5: Contextual Misapplication
- Mistake 6: Neglecting Data Validation
- Mistake 7: Neglecting Bias in Secondary Research
- Best Practices to Avoid Secondary Data Collection Mistakes
- Conclusion
Recommended Reads
Contact us
Summary:
Secondary data collection is a cost-effective and widely used research method, but it can lead to inaccurate business decisions if data quality is not properly assessed. Common mistakes include using outdated datasets, relying on unreliable sources, failing to cross-check information, mishandling missing data, applying data in the wrong context, neglecting data validation, and overlooking potential bias. Organizations can avoid these issues by implementing strong source verification, data validation, cross-checking procedures, bias assessments, and documentation standards. By following these best practices, businesses can improve data accuracy, strengthen decision-making, and maximize the value of secondary research.
More and more often, corporations rely on secondary data sources such as datasets that were previously published, archives, administrative data sets, and desk research in order to make business decisions. However, the use of secondary data without proper validation poses serious risks. If your secondary data is not reliable, your whole process of business intelligence will be flawed from the very beginning of your analysis [1].
In this guide, we will disclose the most damaging mistakes in secondary data collection done by B2B researchers and corporate analysts, as well as how to correct these issues within your research team.
What Are Common Mistakes in Secondary Data Collection?
The secondary data collection mistakes are those that may arise when collecting, verifying, or using data which exists in certain sources like databases, document-based research, governmental databases, or third-party market research reports.
Unlike primary data mistakes, such mistakes will go unnoticed because the source will be perceived as reliable at first. In order to understand how secondary data collection mistakes happen, read our article on secondary data collection in market and healthcare research.
Common Mistakes in Secondary Data Collection and How to Fix Them

Corporate Data Collection Mistake 1 - Utilization of Outdated Datasets
The utilization of archival data without checking its publication dates is among the most frequent corporate data collection mistakes. Markets and consumer behaviour change too quickly. A dataset that was considered to be of the top quality just two years ago might produce extremely misleading corporate research results today.
Solution: Check the publication and last update dates of each dataset you use. Set a recency benchmark specific to your industry – usually 12-24 months for B2B market datasets and up to 6 months for other industries [2].
Corporate Data Collection Mistake 2 - Not Checking Source Credibility
All sources aren’t equal. If you use data from non-peer reviewed, non-verified or biased sources you add systematic data bias to your corporate research analysis. Corporate data pipelines based on such documental research don’t meet executives’ requirements.
Solution: Use government sources, academic articles and well-known research institutions as your primary secondary sources. Follow the source verification guidelines before onboarding any new dataset in your pipeline.
See how our Secondary Quantitative Research ensure data collection from verified sources only [3].
Mistake 3: Not Cross Checking Data
It is unlikely that just one secondary source will be enough for the accuracy of your enterprise data. The common B2B market research mistakes come from a team using only one published dataset, and not cross-checking information to confirm the reliability of your information.
Solution: Develop policies for mandatory cross checking of data by validating important metrics using at least two independent secondary data sources prior to using the information for any organizational decisions [4].
To get the process started, use our How to Collect Secondary Data for Statistical Analysis guide.
Mistake 4: Failure to Handle Missing Data
The problem of missing data in the research process is perhaps one of the trickiest secondary data problems. Missing data is commonly treated like zero values when it comes to administrative data or published data sources. Instead, you can just omit all missing values and introduce a selection bias.
Solution: Introduce standard processes of data cleansing prior to analysis. If necessary, use methods of imputation or describe missing patterns [4].
Mistake 5: Contextual Misapplication
Secondary data collected from one context is always inappropriately applied to another one. A dataset created based on consumer retail behaviors, for example, can hardly be directly used to inform B2B market data decision-making without appropriate contextual modifications. Such misapplication of secondary sources is the main reason behind bad data quality effecting decision-making.
Fix: Before you incorporate any secondary source in your research, assess the methodological, population and geographical context of the data collection. Make sure the context of the dataset matches your goals precisely [3].
Mistake 6: Neglecting Data Validation
Neglecting formal data validation procedures results in mistakes being carried through the entire analysis of secondary data. Mistakes in corporate analytics are especially frequent among the groups that believe published data is of high quality — in fact, even the most authoritative publications include formatting mistakes, duplication, and definitional inconsistencies in their datasets.
Fix: Perform systematic quality assurance of all the secondary data, including detection of duplicates, range validation and definition consistency checks. It is critical that data validation is performed before any secondary dataset goes into analysis.
Learn more about Data Collection for Business frameworks, where validation is included in each phase of the research [2].
Mistake 7: Neglecting Bias in Secondary Research
Bias in data obtained from secondary research may come from the methodology used when collecting the data, the biases held by the publication body due to political and business interests, or unrepresentative samples in the primary research. Research teams not able to identify such biases will introduce systematic errors that cannot be corrected after analysis.
Solution: Check the methodology of all secondary sources. Determine the funding source, sample size, and identified limitations in the primary study. This is particularly important for B2B market research and enterprise data accuracy considerations.
Our Secondary Qualitative Research Services include a structured bias assessment review for every source used in your project.
Best Practices to Avoid Secondary Data Collection Mistakes
In order to prevent making errors while working with secondary data, a systematic and replicable approach rather than mere care in a single project should be applied. Here are some best practices which should be adhered to by all decision-grade corporate data workflows:
- Create a hierarchical structure of sources for every research area that would give preference to governmental information, peer-reviewed literature and known datasets over commercial publications.
- Provide mandatory data validation and cleaning checks before using any secondary data for analysis.
- Keep records about the publication date, last update, and reliability rating of every secondary source currently being used.
- Use cross checking procedures for all the critical metrics, indicating discrepancies to senior analysts [4].
- Conduct methodology reviews of all the third-party secondary sources, including sampling techniques, data biases, and geographical/demographic constraints.
- Keep records of all missing data and methods of their treatment.
For a full walkthrough of how to build these standards into your research, read our article on Secondary Quantitative Data Collection.
Conclusion
All errors made during secondary data collection can be easily avoided by using proper validation techniques, source verification processes, and quality controls. From old archival information to unmanaged bias during secondary research, there is always a way out for all types of errors in case a corporation wants to improve its data accuracy [3].
Statswork specializes in helping businesses eliminate these errors through expert Secondary Data Collection Services, including Secondary Quantitative Research and Secondary Qualitative Research. Our statisticians apply rigorous cross-checking, data validation and cleaning, and bias assessment protocols — so your research produces decision-grade outputs, not costly mistakes. If your organization is concerned about the accuracy of its existing secondary data pipelines, connect with our team today.
Frequently asked questions:
Secondary data collection is the process of obtaining and analyzing information that has already been collected and published by other researchers, organizations, government agencies, or institutions for a different purpose.
The four main types of data collection are surveys, interviews, observations, and secondary data review, each of which helps researchers gather information based on the objectives and requirements of their study.
Financial data can be collected from public financial statements, regulatory filings, stock market reports, government databases, and industry publications. The collected information should be verified and compared across multiple sources for accuracy. Proper organization and analysis of the data help support business valuation, risk assessment, and strategic planning.
Secondary data can be collected through government publications, academic journals, industry and market research reports, company records and annual reports, and online databases or digital archives.
The two main types of secondary data are internal secondary data, which comes from an organization’s own records, and external secondary data, which is obtained from outside sources such as government agencies, research institutions, and industry reports.
The seven steps of data collection for research include defining the research objectives, identifying the required data, selecting suitable data sources, choosing the data collection method, gathering the data, validating and cleaning the data, and finally analyzing and interpreting the results.
Reference:
- Baldwin, J. R., Pingault, J. B., Schoeler, T., Sallis, H. M., & Munafò, M. R. (2022). Protecting against researcher bias in secondary data analysis: challenges and potential solutions. European journal of epidemiology, 37(1), 1-10.https://link.springer.com/article/10.1007/s10654-021-00839-0
- Thibault, R. T., Kovacs, M., Hardwicke, T. E., Sarafoglou, A., Ioannidis, J. P., & Munafò, M. R. (2023). Reducing bias in secondary data analysis via an Explore and Confirm Analysis Workflow (ECAW): a proposal and survey of observational researchers. Royal Society Open Science, 10(10), 230568.https://pmc.ncbi.nlm.nih.gov/articles/PMC10565389/
- Cheong, H. I., Lyons, A., Houghton, R., & Majumdar, A. (2023). Secondary qualitative research methodology using online data within the context of social sciences. International Journal of Qualitative Methods, 22, 16094069231180160.https://journals.sagepub.com/doi/full/10.1177/16094069231180160
- Sharma, D. N. K. (2022). Instruments used in the collection of data in research. Available at SSRN 4138751.https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4138751