- Services
- Data Analysis services
- Sample Work
Data Analysis services
- Secondary Qualitative Research Services
- Secondary Quantitative Research Services
- Meta-Analysis Research services
- Sample Work

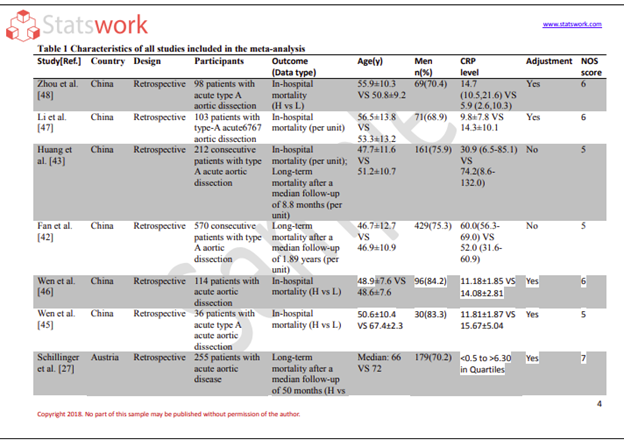
Meta-Analysis Research Services
- Data Collection Services
- Sample Work
Data Collection Services
- Statistical & Biostatistics services
- Sample Work
Statistical Programming & Biostatistics services
- Data Management Services
- Sample Work
Data Management Services
- Research methodology services
- Sample Work
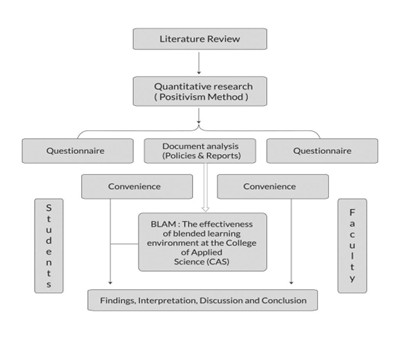
Research methodology services
- Tool Development Services
- Sample Work
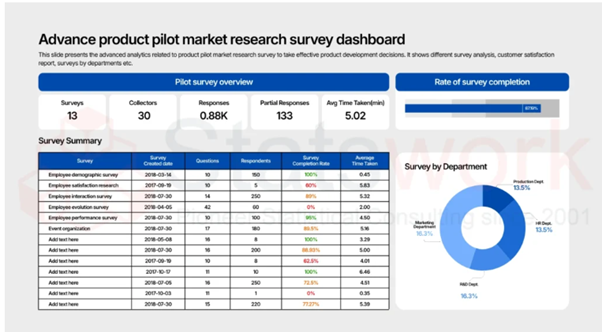
Tool development services
- Statistical Interpretation services
-
Statistical Interpretation services
- Sample Work
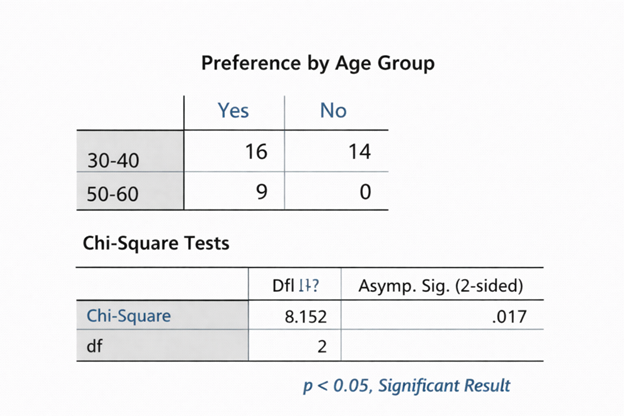
Statistical Interpretation services
-
- Sample Size Calculation Services
-
Sample Size Calculation Services
- Sample Work
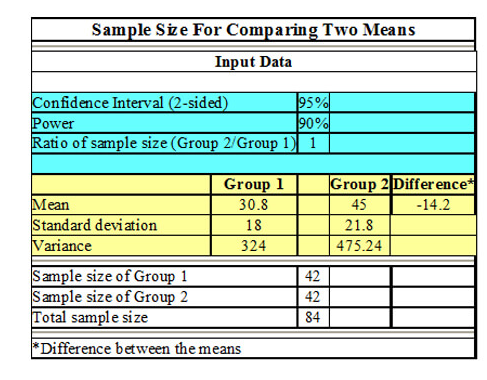
Sample Size Calculation Services
-
- AI & ML Services
-
Artificial Intelligence and Machine Learning Services
- Sample Work
Artificial Intelligence and Machine Learning Services
-
- Meaningful Visualization Services
- Thought Leadership Services
- Report Generation Services
-
Report generation Service
- Sample Work

Report generation Services
-
- Data Analysis services
- Industries
- About Us
- Blog
- Insights
- Contact Us
- Services
- Data Analysis services
- Sample Work
Data Analysis services
- Secondary Qualitative Research Services
- Secondary Quantitative Research Services
- Meta-Analysis Research services
- Sample Work
Meta-Analysis Research Services
- Data Collection Services
- Sample Work
Data Collection Services
- Statistical & Biostatistics services
- Sample Work
Statistical Programming & Biostatistics services
- Data Management Services
- Sample Work
Data Management Services
- Research methodology services
- Sample Work
Research methodology services
- Tool Development Services
- Sample Work
Tool development services
- Statistical Interpretation services
-
Statistical Interpretation services
- Sample Work
Statistical Interpretation services
-
- Sample Size Calculation Services
-
Sample Size Calculation Services
- Sample Work
Sample Size Calculation Services
-
- AI & ML Services
-
Artificial Intelligence and Machine Learning Services
- Sample Work
Artificial Intelligence and Machine Learning Services
-
- Meaningful Visualization Services
- Thought Leadership Services
- Report Generation Services
-
Report generation Service
- Sample Work
Report generation Services
-
- Data Analysis services
- Industries
- About Us
- Blog
- Insights
- Contact Us
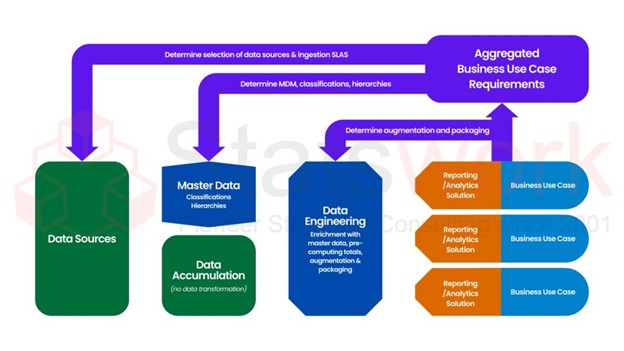
Secondary Data for Statistical Modeling and Predictive Analysis
Meta Analysis Service
- What is Secondary Data in Research?
- Why Secondary Data is Valuable for Predictive Research
- How Secondary Data Supports Predictive Analysis
- How to Use Secondary Data for Statistical Modeling
- Statistical Techniques and Machine Learning with Secondary Data
- Challenges and Best Practices for Using Secondary Data in Predictive Research
- Conclusion
Recommended Reads
Contact us
Introduction to Secondary Data for Statistical Modeling and Predictive Analysis
Secondary data offers useful research data sets, as well as useful public data sets, which are useful for statistical modeling and analysis by a researcher. Statistical modeling with the help of secondary data enables a researcher to recognize patterns and relationships without gathering more data [1].
Predictive analysis with the help of secondary data sets, along with regression analysis and machine learning data, enables a researcher to forecast trends with the help of secondary data in fields like healthcare.
What is Secondary Data in Research?
Secondary data, on the other hand, is considered a collection of data that is already gathered, processed, and published by other researchers, organizations, and institutions. This means that instead of gathering more information, researchers can utilize existing information for further analysis and interpretation.
In most cases, when conducting a study, researchers can use statistical modeling using existing secondary data for further analysis and interpretation. This means that researchers can apply different techniques, such as regression analysis, for further analysis of different variables [2].
Additionally, with existing research datasets, researchers can carry out predictive analysis using existing secondary data, where they are able to analyze existing data for further prediction of what could occur in the future. This is mostly applied in different fields, such as healthcare, economics, and social science, where existing secondary data in predictive research enables researchers to carry out further analysis efficiently.
Why Secondary Data is Valuable for Predictive Research
| Access to Large Research Data Sets | Secondary data offers large research data sets that allow a researcher to perform predictive analysis with many data samples. |
| Support Statistical Modeling | Secondary data supports the use of statistical modeling for research. This helps a researcher to identify patterns, relationships, and trends in the data sets available for analysis [3]. |
| Enables Advanced Predictive Analysis | Predictive analysis of secondary data sets helps a researcher to make predictions on the results based on the data available for analysis. This helps to enhance the accuracy of research results. |
| Useful for Regression and Machine Learning Models | Secondary data is useful for applying various data modeling techniques like regression analysis to make predictions on the data available for analysis. |
| Cost and Time Efficient | Using secondary data for predictive research helps a researcher to avoid the costs involved in collecting data for research purposes [4]. |
| Widely Used in Healthcare Research | Secondary data is widely used for statistical modeling in healthcare research. |
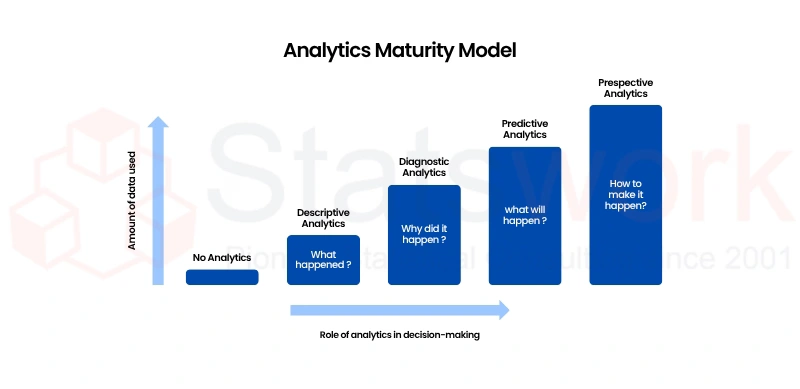
How Secondary Data Supports Predictive Analysis
- Offers Large Research Datasets Secondary data provides large datasets for research, which can aid a researcher in carrying out reliable predictive analysis.
- Identifies Patterns and Trends By carrying out predictive analysis on secondary data, a researcher can identify the patterns associated with the data. This can aid a researcher in identifying the relationships between the variables associated with the data [5].
- Support Statistical Modeling Secondary data can aid a researcher in carrying out statistical modeling techniques such as regression analysis to perform predictive analysis.
- Enhance Machine Learning Secondary data provides valuable machine learning data to enhance the machine learning models developed by a researcher.
- Enables Forecasting By carrying out predictive analysis on secondary data, a researcher can perform forecasting [3].
How to Use Secondary Data for Statistical Modeling
| Key Aspect | Description |
| Provides Large Research Datasets | Secondary data offers a researcher large datasets that can be very useful in carrying out reliable predictive analysis research. |
| Identifies Patterns and Trends | By using secondary data in carrying out predictive analysis research, a researcher can identify patterns and trends that exist between various data variables. |
| Supports Statistical Modeling | Researchers use secondary data in carrying out statistical modeling techniques, including regression analysis, in predictive analysis modeling. |
| Enhances Machine Learning Models | Secondary data offers a researcher useful machine learning data that can be used in enhancing predictive modeling accuracy [4]. |
| Enables Forecasting and Decision-Making | By using predictive analysis techniques in carrying out secondary data analysis, a researcher can forecast data trends for decision-making. |
Statistical Techniques and Machine Learning with Secondary Data
- Regression Analysis Regression analysis is a statistical analysis tool that is used for secondary data analysis.
- Machine Learning Models The availability of research data sets and machine learning data helps to create an algorithm for predictive analysis.
- Predictive Analysis Using Secondary Datasets The research data sets are used for predictive analysis using secondary data sets from public data sources for trend analysis and prediction results.
- Pattern Identification The application of statistical analysis and machine learning on secondary data for predictive research helps to identify patterns in complex data sets [2].
Challenges and Best Practices for Using Secondary Data in Predictive Research
| Challenge / Best Practice | Description |
| Data Quality Issues | With secondary data in predictive research, the quality of available datasets for research can impact the results obtained in predictive analysis. |
| Data Relevance and Compatibility | The relevance of some data in public domain data for the research goal might be an issue; hence, secondary data for statistical modeling is important. |
| Handling Missing or Inconsistent Data | Cleaning and preprocessing the data before carrying out predictive analysis using secondary data for the research is important [4]. |
| Choosing Appropriate Techniques | The use of techniques such as regression analysis and machine learning can help a researcher understand how to use secondary data for statistical modeling effectively. |
| Data Validation and Reliability | Using machine learning data and verifying the reliability of the data can help in achieving high accuracy in predictive analysis. |
Conclusion
Using secondary data in statistical modeling for research allows one to make effective predictive analysis using existing datasets from other research and available data. Regression analysis and machine learning data can be effectively used in identifying patterns and improving predictive analysis in secondary data [5]. For reliable and well-structured secondary data, one can use professional secondary data collection services.
Strengthen your predictive research with reliable datasets by using professional secondary data collection services from Statswork for accurate statistical modeling and analysis.
References:
- Hohmann, E., Wetzler, M. J., & D’Agostino Jr, R. B. (2017). Research pearls: The significance of statistics and perils of pooling. Part 2: Predictive modeling. Arthroscopy: The Journal of Arthroscopic & Related Surgery, 33(7), 1423-1432. https://www.sciencedirect.com/science/ar
- Celestin, M. (2021). The Role of Predictive Analytics in Supplier Negotiations and Procurement Cost Optimization. Brainae Journal of Business, Sciences and Technology, 5(6), 882-893. https://www.sciencedirect.com/science/ar
- Breiman, L. (2001). Statistical modeling: The two cultures (with comments and a rejoinder by the author). Statistical science, 16(3), 199-231. https://projecteuclid.org/journals/statistical-science/volume-16/issue-3/Statistical-Modeling–The-Two-Cultures-with-comments-and-a/10.1214/ss/1009213726.full
- Tuli, F. A., Varghese, A., & Ande, J. R. P. K. (2018). Data-driven decision making: A framework for integrating workforce analytics and predictive HR metrics in digitalized environments. Global Disclosure of Economics and Business, 7(2), 109-122. https://pdfs.semanticscholar.org/38be/5b
- Heilman, M., Collins-Thompson, K., & Eskenazi, M. (2008, June). An analysis of statistical models and features for reading difficulty prediction. In Proceedings of the third workshop on innovative use of NLP for building educational applications(pp. 71-79). https://aclanthology.org/W08-0909.pdf