
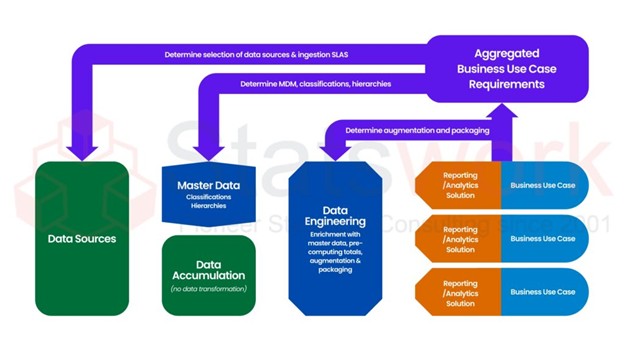


Data Collection
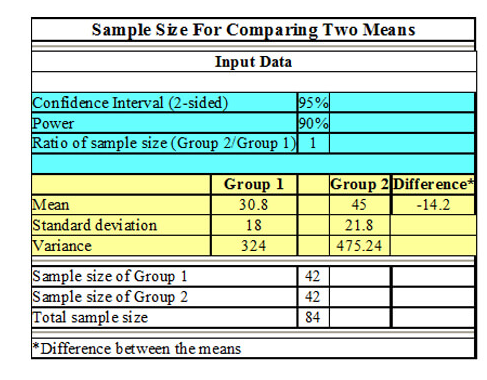
As the data collection methods have extreme influence over the validity of the research outcomes, it is considered as the crucial aspect of the studies
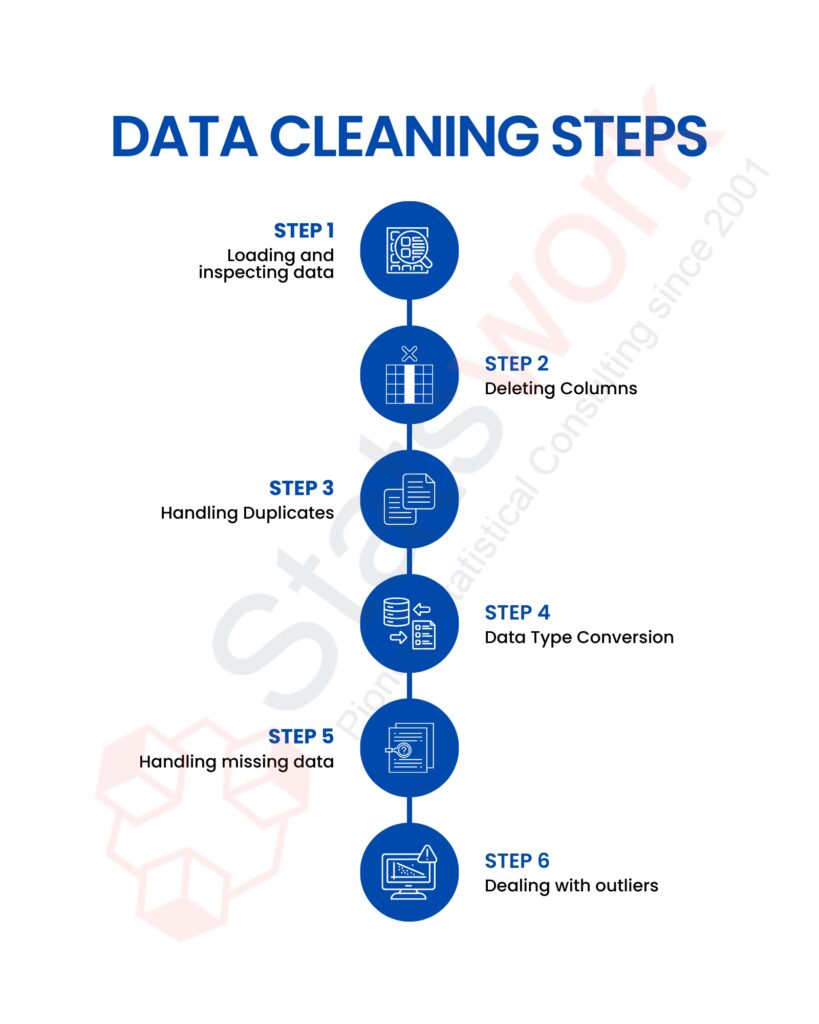
Data cleaning is a process of systematic activities that are carried out with the aim of enhancing the quality of data by eliminating errors, inconsistencies, and redundancies.
- Handling missing data: Replace missing values by applying appropriate methods or delete the records that contain missing values.
- Removing duplicates: Identify duplicate records to avoid bias or over-representation in the dataset.
- Correcting errors: Correct spellings of names incorrectly spelled, wrong nomenclatures or labels, and incorrect entries.
- Standardizing data: Convert all values to the same standard format within the complete dataset.
- Outlier treatment: Identify anomalous values and determine whether they are to be corrected or retained, depending on the context.
Data cleaning should enhance data accuracy, consistency, and usability.[4]