

What is the definition of Apache Spark?
- Home
- Insights
- Article
- What is the definition of Apache Spark?
Qualitative Research Service
News & Trends
Recommended Reads

Data Collection
As the data collection methods have extreme influence over the validity of the research outcomes, it is considered as the crucial aspect of the studies
What is the definition of Apache Spark?
- 1. Introduction
- 2. DeepHealth’s Diagnostic Suite™: Revolutionizing Radiology Workflows
- 3. Key Features
- 4. AI Impact on National Screening Programs
- 5. SmartMammo™: Enhancing Breast Cancer Screening
- 6. DeepHealth AI Use Cases Across Specialties
- 7. Strategic Collaborations and Ecosystem Expansion
- 8. Impact and Adoption of DeepHealth’s AI Solutions
- 9. Conclusion: The Future of Radiology with AI
- 10. References
Using in-memory computing allows you to process many data sets quickly and easily, providing both increased flexibility and simplicity for developers and analysts. Apache Spark is an example of a distributed computing framework that can accomplish many tasks better than legacy systems such as Hadoop.[1]
Core Features of Apache Spark
Spark is widely used because it has many features that can be used to work with all kinds of data in many ways.
- In-memory computation: Process large amounts of data fast with less disk I/O.
- Fault tolerance: Provide a way to ensure that your data is reliable through replication of data and tracking history of that data.
- Ease of use: Offer APIs for multiple languages to allow for flexible development (Python, Java, Scala, R).
- Complex analytics: Support machine learning, graph processing, and real-time streaming capabilities for advanced analysis purposes.[2]
Components of Apache Spark
Apache Spark has several key parts that are designed to greatly enhance operational capabilities:
- Spark SQL: Tools for the Structured Processing, Querying and Integration of Structured Data processing with RDBMS which provide fast & efficient methods to Analyse data.
- Spark Streaming: Tools used to Manage Real-Time Streaming Data; therefore, you can view and get access to data as it is occurring.
- MLlib: The Machine Learning Library enables you to perform Classification, Regression, Clustering and Recommendation tasks.
- GraphX: Graph and Network Analysis capabilities allow for complex calculations to be carried out on interconnected data.[3]
Apache Spark’s Architecture
Apache Spark has been architected to provide scalable processing, high-performance distributed data processing.
- Master-Slave Architecture: The Driver program controls the execution and coordination of all tasks across all worker nodes.
- Data Partitioning: The data that spark processes is stored in a Resilient Distributed Dataset (RDD), or the DataFrame API, so that it can be easily and efficiently processed in parallel with other datasets.
- Scalability: It can scale from one machine to thousands of machines with minimal effort.
- Parallel Processing: It allows for the concurrent execution of all tasks in the cluster which leads to quicker computation times.[4]

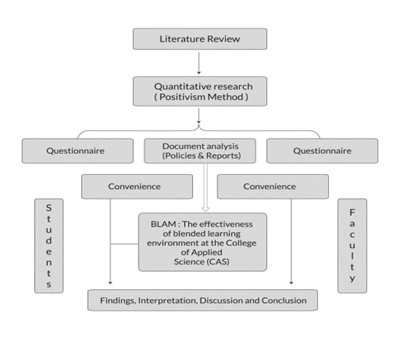
Fig. 1 shows the Apache Spark architecture and its parallel task execution.
Applications of Apache Spark
Application | Description |
Big Data Analytics | Statistical and analytical analysis of large datasets in industries such as healthcare, finance and e-commerce to identify trends and gain business insight. |
Real-time Data Processing | Monitoring and analysing live streaming data (logs, event tracking, monitoring systems). |
Machine Learning & Predictive Modelling | Predictive modelling and machine learning applications for data-driven decision making. |
ETL Pipelines | Efficient Extraction, transformation, & loading of data for analytical use and reporting purposes. |
Business Intelligence & Reporting | Reports, graphs and dashboards that provide you a visual representation of your business processes allowing you to make better decisions.[5] |
Conclusively, Apache Spark has a powerful combination of speed, scalability, and flexibility, which are essential for handling a wide variety of large-scale data workloads including, but not limited to, real-time processing, advanced analytics and intelligent decision support across many different industries.
Build intelligence that evolves, adapts, and scales—StatsWork’s AI & ML for the future ahead.
Reference
- Salloum, S., Dautov, R., Chen, X., Peng, P. X., & Huang, J. Z. (2016). Big data analytics on Apache Spark. International Journal of Data Science and Analytics, 1(3), 145-164. https://link.springer.com/article/10.1007/s41060-016-0027-9
- Meng, X., Bradley, J., Yavuz, B., Sparks, E., Venkataraman, S., Liu, D., … & Talwalkar, A. (2016). Mllib: Machine learning in apache spark. Journal of Machine Learning Research, 17(34), 1-7. https://www.jmlr.org/papers/v17/15-237.html
- Karau, H., & Warren, R. (2017). High performance Spark: best practices for scaling and optimizing Apache Spark. ” O’Reilly Media, Inc.” https://books.google.co.in/books?hl=en&lr=&id=90glDwAAQBAJ&oi=fnd&pg=PP1&dq=Components+of+Apache+Spark&ots
- Awan, A. J., Brorsson, M., Vlassov, V., & Ayguade, E. (2016). Architectural impact on performance of in-memory data analytics: Apache spark case study. arXiv preprint arXiv:1604.08484. https://arxiv.org/abs/1604.08484
- Armbrust, M., Das, T., Torres, J., Yavuz, B., Zhu, S., Xin, R., … & Zaharia, M. (2018, May). Structured streaming: A declarative api for real-time applications in apache spark. In Proceedings of the 2018 International Conference on Management of Data(pp. 601-613). https://dl.acm.org/doi/abs/10.1145/3183713.3190664