

Q & A
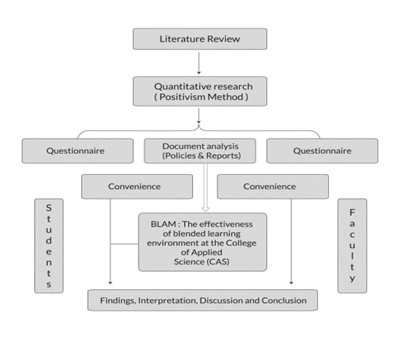
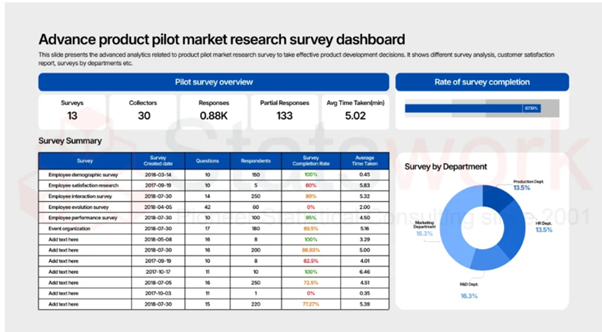
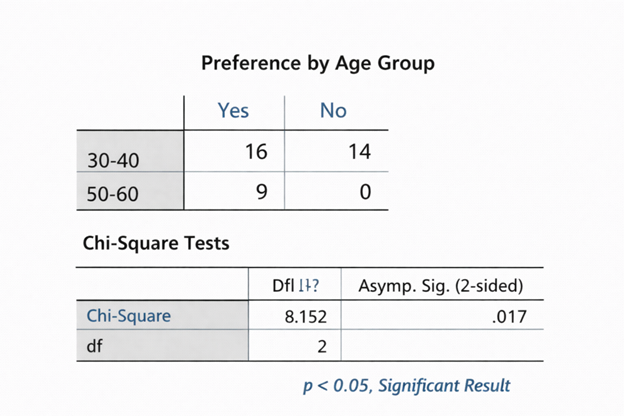
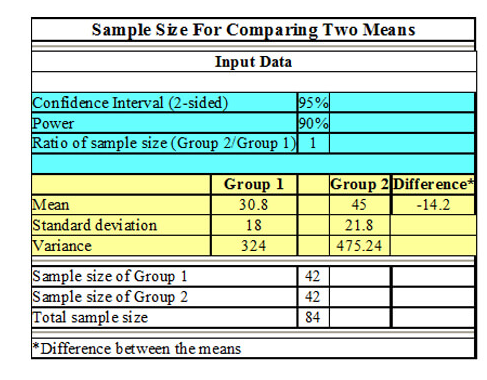
Secondary Data Collection
Q: How do you Tailor Secondary Data to Fit Specific Client Needs or Research Variables?

The following is a step-by-step guide on how to customize secondary data to meet a client’s specific needs/research variables:
Step 1: Familiarize Yourself with the Research Objectives
Before delving into using any secondary data, it is important to first gain an understanding of what the client’s research objectives/research variables are pertaining to. This means understanding what questions the client wants answered, what the research covers and what key variables to concentrate on.
Step 2: Determine what types of secondary sources are appropriate
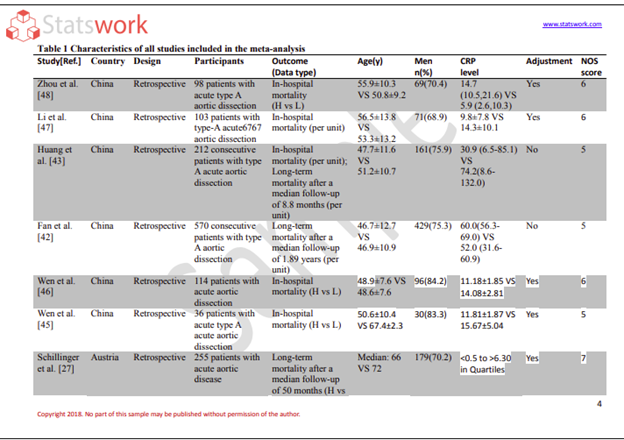
Determine which secondary data sources are appropriate based on the objectives of your project. Secondary data sources may include government publications, academic studies, industry surveys and public data.
Step 3: Determine the quality of secondary data
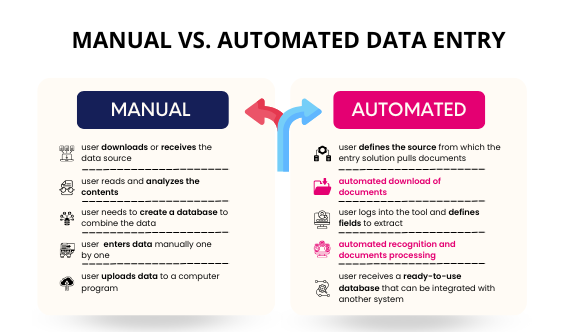
Determine the quality and consistency of the secondary data. You need to look for things like outdated data and formatting discrepancies, and whether data is missing. You also must clean and standardize the data, so that it fulfils the client’s research requirements.
Step 4: Standardize the variable names and unit of measure
The secondary databases may have different definitions or units of measure for the variables being studied. You will have to change the names of the variable and/or the unit of measure to be consistent with the variable names specified by the client.
Step 5: Combine and analyse the cleaned data
Assemble and analyse the combined, cleaned data to meet the needs of the client. The database may contain multiple sources of data that need to be merged; you may also need to add or delete new variables or use statistical analysis techniques to provide insights to answer the client’s research questions. The analysis should concentrate on the research variables that are most important to the client.