
As the data collection methods have extreme influence over the validity of the research outcomes, it is considered as the crucial aspect of the studies
May 2025 | Source: News-Medical
In qualitative research, raw audio can be a trove of information, depicting stories, emotional response and in-depth beliefs. However, unless the raw audio data is transcribed and open coding subsequently performed on it, the data is effectively hidden and in a unstructured state. Transcription and open coding are the missing piece of the puzzle that enables researchers to process voice recordings into knowledge that can be applied to their research. Transforming speech data from interviews, focus groups, or open-ended survey responses into structured, analysable data is a vital step to induction research.
In this guide, we will outline the process from raw-data ingestion to final analysis and discuss how modern tools and expert-processes can help you maximize the outcomes of qualitative research.
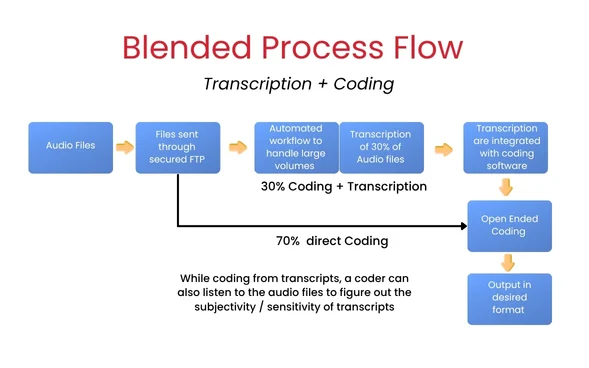
The very first thing you should do to load it up is to collect audio files from all your interviews, discussions or focus groups. You can take all of it as .mp3 or .wav files, or even as transcripts as PDFs. As you collect audio files make sure everything is comprehensible audio, complete sentences, timestamped in some sort of order, and otherwise grouped with sorted metadata (speaker ID, session 1/2 number, …etc)
Organize project transcripts with speaker labels, session identifiers, and time stamps will assist with traceability and allow for more efficient thematic mapping when analysis occurs.
There is no reason to be daunted when it comes to converting voice to useful research insights. By taking a structured approach that incorporates transcription accuracy, purposeful coding, and relevant tools researchers are able to derive rich, qualitative insights from voice data. At Statswork, we take the best of AI efficiencies combined with the human touch to ensure the qualitative data collected is accurate, compliant, and ready for analysis, regardless of project complexity.
Whether you are conducting research as an academic, in healthcare, or as a product strategist, following the workflow of transcription and coding the data in the right way can uncover the true value in each conversation.



WhatsApp us