




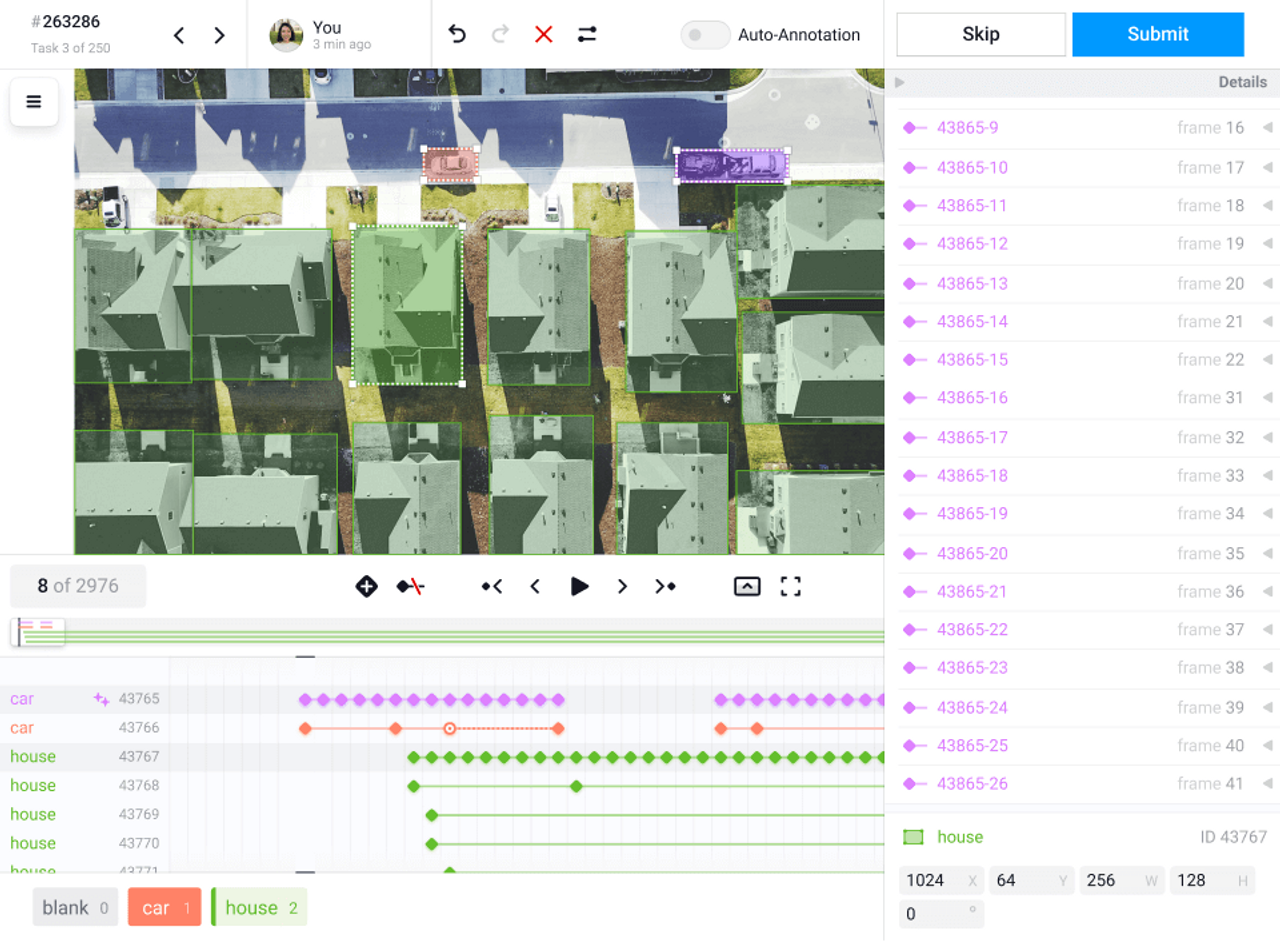
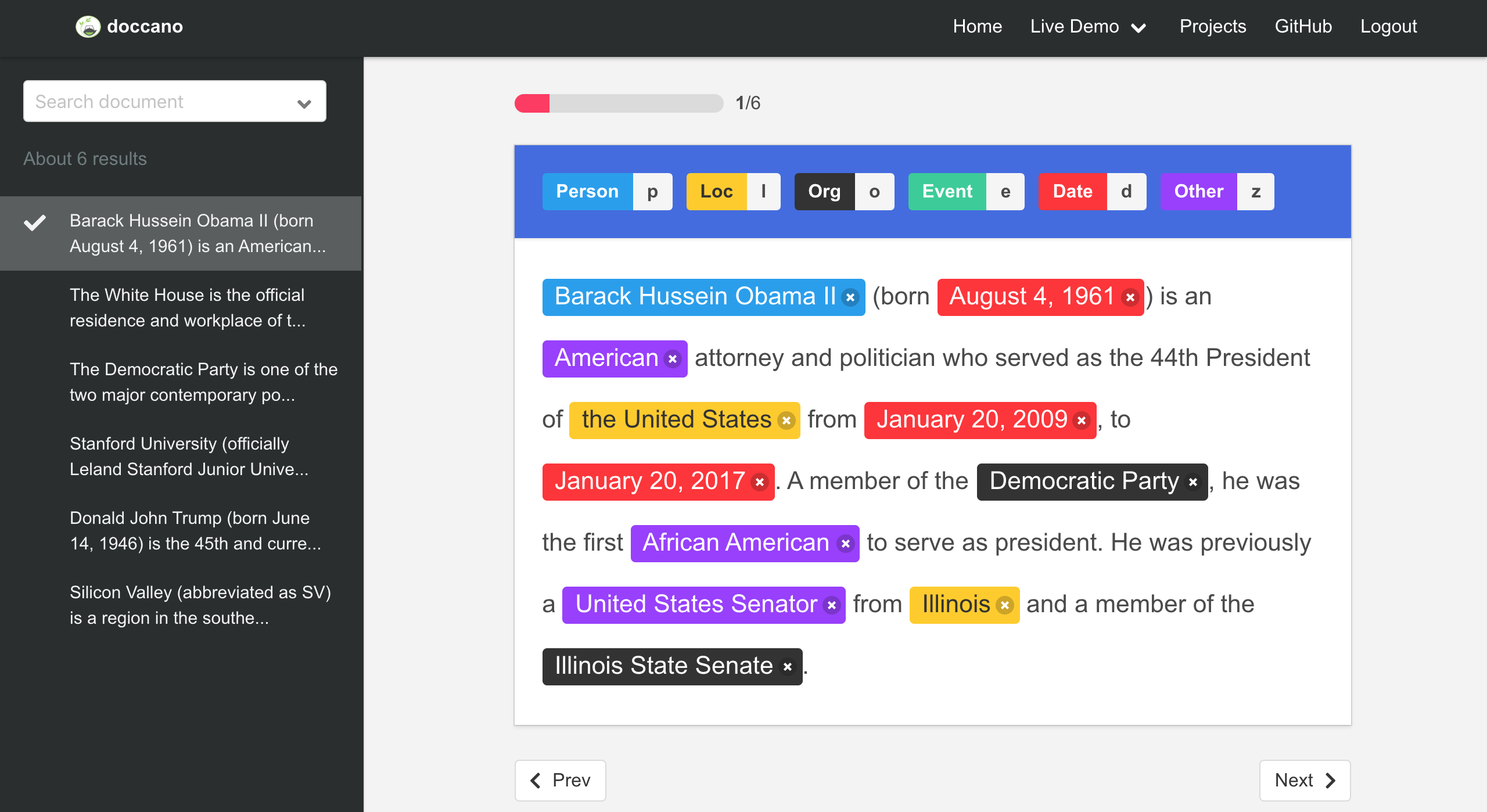
Classifies and labels named entities (e.g., people, organizations, locations, dates) for use in knowledge graphs, legal text analysis, intelligent search engines, and document classification
Identifies the purpose behind text inputs (e.g., queries, commands, feedback), essential for chatbots, voice-based systems, and conversational AI platforms.

Categorizes text based on emotion or tone (positive, negative, neutral) for use in social media monitoring, product feedback systems, and customer sentiment analysis.
Links concepts to a knowledge base to enhance AI comprehension and disambiguate meaning (e.g., “Apple” the brand vs. fruit), improving natural language understanding (NLU).
Traces pronouns or phrases back to the entities they reference (e.g., “John went home. He was tired.”), minimizing contextual ambiguity in language modeling.

Assigns grammatical roles (noun, verb, adjective, etc.) to each word, enabling syntactic parsing, linguistic modeling, and deep NLP structure learning.




Statswork helped us annotate thousands of clinical notes with precise medical terminology. Their domain expertise and attention to detail improved our NLP model performance significantly.
We needed sentiment analysis and product tagging across customer reviews. Statswork’s team delivered clean, consistent text annotations that boosted our recommendation engine.
Annotating complex legal documents requires precision, and Statswork nailed it. Their team understood context, redaction needs, and legal semantics perfectly.
Statswork enabled us to build a robust fraud detection model by annotating transaction descriptions with context-specific labels. Fast, accurate, and dependable.





