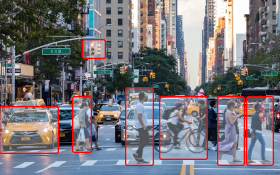

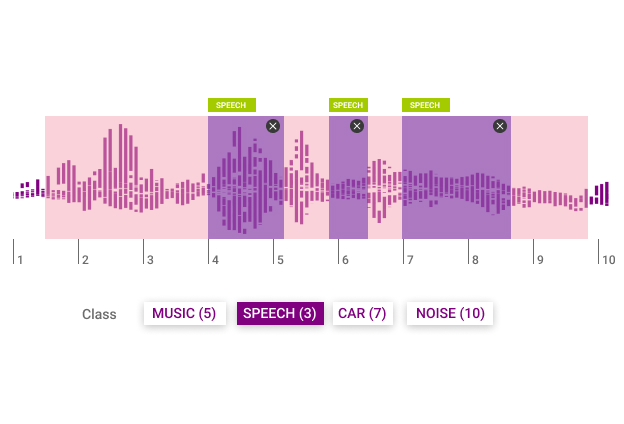














As planned the initial step is to gather the requirements for the project - project goals, data types, and specific information unique to the domain. Here we will scope the project, investigate the use case and desired formats of the annotation, so that we can establish standards and make sure we are aligned from day one.
Your raw data (text, image, audio or video) will be cleaned and anonymized (if necessary) and prepared before being annotated by our team to verify the accuracy for your project. We confirm that your data is formatted and structured appropriately to fit with your intended annotation guidelines and machine learning goals.
Consistency in the annotation process can only take place after setting up the guidelines based on your ultimate goals. We outline the structures of the labels, any metadata requirements, and create measures of quality based on the above - essentially standards to maintain quality.
Your project manager will be responsible for your team of dedicated and trained annotators to ensure your project is labelled to a high quality and delivered on time. Quality comes first and is at the heart of our practices, that means we continuously monitor performance throughout.
In addition to continually checking quality, and receiving client feedback and its iteration, we QA the annotations and enhance them. Each dataset receives our layered QA and achieves the accuracy rates needed for your high-performing AI models
At last, when your data clears all validation - it is ready for delivery, in whichever format you want (e.g., JSON, CSV, COCO). We are happy to help with future iterations or scaling
Thanks to the precise medical image annotation provided by the team, our AI model achieved clinical-grade accuracy. This directly contributed to our publication in the Journal of Medical Imaging and Health Informatics.
We were impressed by the team's expertise in clinical text annotation. Their work helped us build an NLP pipeline that led to our successful article in the International Journal of Medical Informatics.
The annotated dataset they delivered met all journal standards, and their adherence to HIPAA compliance was commendable. Our study was published in the BMC Medical Informatics and Decision-Making journal.
The Statswork team helped us annotate and label a massive dataset for drug discovery, contributing to our manuscript accepted in Frontiers in Pharmacology. Their scientific accuracy was outstanding






